普雷斯顿SH:各国人口的死亡率模式:特别提及有记录的死亡原因。纽约:学术出版社1976.
谷歌学者
Murray CJL, Lopez AD:全球死亡率、残疾和危险因素的贡献:全球疾病负担研究。《柳叶刀》1997年,349:1436 - 1442。
中科院PubMed谷歌学者
Peto R, Lopez AD, Boreham J, Thun M, Heath C Jr:发达国家烟草造成的死亡率。《柳叶刀》1992年,339:1268 - 1278。
中科院PubMed谷歌学者
McGinnis JM, Foege WH:美国的实际死亡原因《美国医学会杂志》1993年,270:2207 - 2212。
中科院PubMed谷歌学者
单E, Robson L, Rehm J,谢欣:加拿大酒精、烟草和非法药物使用导致的发病率和死亡率。美国公共卫生杂志1999年,89:385 - 390。
中科院PubMed公共医学中心谷歌学者
Smith KR, Corvalan CF, Kjellstrom T:全球健康不佳有多少可归因于环境因素。流行病学1999年,10:573 - 584。
中科院PubMed谷歌学者
基米-雷克南:史密斯印度室内空气污染造成的国家疾病负担。美国国家科学研究院2000年,97:13286 - 13293。
中科院PubMed公共医学中心谷歌学者
李,马卡斯基尔,郭斯玛,曼德利克J:职业因素造成的全球疾病和伤害负担。流行病学1999年,10:626 - 631。
中科院PubMed谷歌学者
昆兹利N,凯泽R,梅迪纳S,斯图尼卡M,夏奈尔O,菲利格P,亨利M,霍拉克F Jr,普博尼埃-特希尔V,奎纳尔P,等.:室外和交通相关空气污染对公共健康的影响:欧洲评估。《柳叶刀》2000年,356:795 - 801。
中科院PubMed谷歌学者
Willet WC:平衡生活方式和疾病预防的基因组学研究。科学2002年,296:695 - 698。
谷歌学者
Manton KG, Singer BH, Suzman RM:预测老年人口的健康。纽约:Springer-Verlag出版社1993.
谷歌学者
Manton KG, Stallard E, Singer BH:预测美国未来人口规模和健康状况的方法老年人口。见:老龄化经济学研究(编辑:Wise DA)。芝加哥:芝加哥大学出版社,1994年。
谷歌学者
艾亚欣,曼顿KG,斯特拉德E:依赖竞争风险:一个随机过程模型。数学生物学杂志1986年,24:119 - 140。
中科院PubMed谷歌学者
知更鸟JM:持续暴露期死亡率研究中因果推断的新方法——健康工作者生存效应控制的应用。数学建模1986年,7:1393 - 1512。
谷歌学者
知更鸟JM:"持续暴露期死亡率研究中因果推断的新方法——健康工人生存效应控制的应用"的增编。计算机与数学及其应用1987年,14:917 - 921。
谷歌学者
罗宾斯JM,格陵兰S:危险暴露造成的预期寿命损失年数的可估计性和估计。医学统计学1991年,10:79 - 93。
中科院PubMed谷歌学者
Robins JM,绿地S, H富昌:时变暴露对重复二元结果边际均值的因果效应估计。美国统计协会杂志1999年,94:687 - 700。
谷歌学者
知更鸟JM:关联,因果关系和边际结构模型。综合1999年,121:151 - 179。
谷歌学者
知更鸟JM:作为因果推断工具的边际结构模型与结构嵌套模型。见:流行病学中的统计模型(编辑:Halloran E)。纽约:施普林格Verlag 1999。
谷歌学者
Murray CJL, Lopez AD:健康风险的可比量化:全球疾病负担的教训。流行病学1999年,10:594 - 605。
中科院PubMed谷歌学者
穆雷CJL:重新考虑残疾。列入:全球疾病负担(编辑:Murray CJL, Lopez AD)。马萨诸塞州剑桥:哈佛大学公共卫生学院(代表世界卫生组织和世界银行)1996年。
谷歌学者
Murray CJL, Salomon J, Mathers CD, Lopez AD, Lozano R(编者):人口健康测量概要:概念、伦理、测量和应用。日内瓦:世界卫生组织2002.
谷歌学者
Mathers CD, Ezzati M, Lopez AD, Murray CJL, Rodgers AD:人口健康综合指标的因果分解。见:人口健康的概要措施:概念、伦理、测量和应用(编辑:Murray CJL, Salomon J, Mathers CD, Lopez AD)。日内瓦:世界卫生组织,2002年。
谷歌学者
世界卫生组织(卫生组织):疾病和相关健康问题的国际统计分类,第十版。日内瓦:世界卫生组织1992.
谷歌学者
马尔多纳多G,绿地S:估计因果效应。国际流行病学杂志2002年,31:422 - 429。
PubMed谷歌学者
Rothman KJ:的原因。美国流行病学杂志1976年,104:587 - 592。
中科院PubMed谷歌学者
莱文ML:肺癌在人类中的发生。国际反革命联盟学报1953年,9:531 - 541。
中科院PubMed谷歌学者
MacMahon B, Pugh TF:流行病学:原则和方法。波士顿:利特尔布朗公司1970.
谷歌学者
Cole P, MacMahon B:病例对照研究中的归因风险百分比。英国预防和社会医学杂志1971年,25:242 - 244。
中科院PubMed公共医学中心谷歌学者
比赛当天艳阳高照的操作系统:因特定暴露、特性或干预而引起或预防的疾病比例。美国流行病学杂志1974年,99:325 - 332。
中科院PubMed谷歌学者
Ouellet BL, Romeder JM, Lance JM:加拿大吸烟和有害饮酒导致的过早死亡率。美国流行病学杂志1979年,109:451 - 463。
中科院PubMed谷歌学者
Eide GE, Heuch I:可归因分数:基本概念及其可视化。医学研究中的统计方法2001年,10:159 - 193。
中科院PubMed谷歌学者
Uter W, Pfahlberg A:量化归因风险方法在医疗实践中的应用。医学研究中的统计方法2001年,10:231 - 237。
中科院PubMed谷歌学者
格陵兰岛史:推导标准化发病率和可归因分数估计方法的偏差。医学统计学1984年,3:131 - 141。
中科院PubMed谷歌学者
洛克希尔B纽曼B温伯格C:使用和滥用人口归因分数。美国公共卫生杂志1998年,88:15 - 19。
中科院PubMed公共医学中心谷歌学者
绿地S,罗宾斯JM:可归因分数定义与解释中的概念问题。美国流行病学杂志1988年,128:1185 - 1197。
中科院PubMed谷歌学者
Drescher K, Becher H:从病例对照数据估计广义影响分数。生物识别技术1997年,53:1170 - 1176。
中科院PubMed谷歌学者
沃尔特SD:预防多因素疾病。美国流行病学杂志1980年,112:409 - 416。
中科院PubMed谷歌学者
格陵兰岛史:流行病学措施政策使用的因果理论。见:人口健康的概要措施:概念、伦理、测量和应用(编辑:Murray CJL, Salomon J, Mathers CD, Lopez AD)。日内瓦:世界卫生组织,2002年。
谷歌学者
波尔斯J,第N天:解读全球疾病负担。《柳叶刀》2002年,360:1342 - 1343。
PubMed谷歌学者
普德迪IB,拉基奇V,迪米特SB,贝林LJ:饮酒方式对心血管疾病的影响及心血管危险因素研究综述上瘾1999年,94:649 - 663。
中科院PubMed谷歌学者
Ezzati M, Lopez AD, Rodgers A, Vander Hoorn S, Murray CJL,比较风险评估合作小组:选定的主要危险因素和全球和区域疾病负担。《柳叶刀》2002年,360:1347 - 1360。
PubMed谷歌学者
MacMahon S, Peto R, Cutler J, Collins R, Sorlie P, Neaton J, Abbott R, Godwin J, Dyer A, Stamler J:血压、中风和冠心病。第一部分,血压的长期差异:校正回归稀释偏倚的前瞻性观察研究。《柳叶刀》1990年,335:765 - 774。
中科院PubMed谷歌学者
陈震,Peto R, Collins R, MacMahon S,陆杰,李伟:低胆固醇人群血清胆固醇浓度与冠心病的关系英国医学杂志1991年,303:276 - 282。
中科院PubMed公共医学中心谷歌学者
东部中风与冠心病合作研究小组:东亚血压、胆固醇与中风。《柳叶刀》1998年,352:1801 - 1807。
谷歌学者
前瞻性研究合作:胆固醇、舒张压和中风:45个前瞻性队列中45,000人的13000次中风。《柳叶刀》1995年,346:1647 - 1653。
谷歌学者
卡瓦略JJ,巴鲁兹RG,霍华德PF,波尔特N,阿尔帕斯MP,弗兰科LJ,马科皮托LF,斯普纳VJ,戴尔AR,艾略特P:INTERSALT研究中四个偏远人群的血压。高血压1989年,14:238 - 246。
中科院PubMed谷歌学者
何俊,Klag MJ, Whelton PK,陈建勇,莫JP,钱MC, MP S,何gq:迁移、血压模式和高血压:彝族移民研究。美国流行病学杂志1991年,134:1085 - 1101。
中科院PubMed谷歌学者
何俊、唐玉春、Tell GS、莫PS、何gq:迁徙对血压的影响:彝族研究。流行病学1991年,2:88 - 97。
中科院PubMed谷歌学者
巴恩斯R:新几内亚人和澳大利亚人血压和血液胆固醇水平的比较。澳大利亚医学杂志1965年,1:611 - 617。
中科院PubMed谷歌学者
Mann GV, Shaffer RD, Anderson RS, Sandstead HH:马赛人的心血管疾病动脉粥样硬化杂志1964年,289 - 312。
谷歌学者
拉罗萨,何杰,武普图里S:他汀类药物对冠状动脉疾病风险的影响:随机对照试验的荟萃分析美国医学会杂志1999年,282:2340 - 2346。
中科院谷歌学者
皮尼奥内M,菲利普斯C,莫罗C:冠心病一级预防中使用降脂药物:随机试验荟萃分析英国医学杂志2000年,321:983 - 986。
中科院PubMed公共医学中心谷歌学者
Corrao G, Rubbiati L, Bagnardi V, Zambon A, Poikolainen K:酒精与冠心病:一项meta分析。上瘾2000年,95:1505 - 1523。
中科院PubMed谷歌学者
Yerushalmy J, Palmer CE:慢性疾病病因调查方法初探。慢性疾病杂志1959年,108:27-40。
谷歌学者
Corvalan CF, Kjellstrom T, Smith KR:健康、环境和可持续发展:确定促进行动的联系和相互作用。流行病学1999年,10:656 - 660。
中科院PubMed谷歌学者
埃文斯:因果关系与疾病:亨利-科赫假设再认识。耶鲁生物与医学杂志1976年,49:175 - 195。
中科院PubMed公共医学中心谷歌学者
埃文斯:因果与疾病:时间旅程。美国流行病学杂志1978,108:249 - 258。
中科院PubMed谷歌学者
罗斯曼KJ,绿地S:现代流行病学。费城:Lippincott-Raven1998.
谷歌学者
格陵兰岛史:流行病学文献综述中的定量方法。流行病学评论1987年,9:外墙面。
中科院PubMed谷歌学者
Patz JA, McGeehin MA, Bernard SM, Ebi KL, Epstein PR, Grambsch A, Gubler DJ, Reiter P, Romieu I, Rose JB,等.:气候变异和变化对美国健康的潜在影响:美国国家评估卫生部门报告执行摘要环境卫生观点2000年,108:367 - 376。
中科院PubMed公共医学中心谷歌学者
罗杰斯DJ,伦道夫SE:疟疾在未来变暖的世界中的全球传播。科学2000年,289:1763 - 1766。
中科院PubMed谷歌学者
Reiter P:气候变化与蚊媒疾病。环境卫生观点2001年,109:141 - 161。
PubMed公共医学中心谷歌学者
Craig MH, Snow RW, le Sueur D:撒哈拉以南非洲基于气候的疟疾传播分布模型。寄生虫学今天1999年,15:105 - 111。
中科院PubMed谷歌学者
Martens P, Kovats RS, Nijhof S, de Vries P, Livermore MTJ, Bradley DJ, Cox J, McMichael AJ:气候变化和未来人口面临疟疾风险。全球环境变化-人与政策层面1999年,9:S89-S107。
谷歌学者
赖斯AL,萨科L,海德A,布莱克RE:营养不良是发展中国家与传染病相关的儿童死亡的根本原因。世界卫生组织公报2000年,108:367 - 376。
谷歌学者
Smith KR, Samet JM, Romieu I, Bruce N:发展中国家的室内空气污染与儿童急性下呼吸道感染。胸腔2000年,55岁:518 - 532。
中科院PubMed公共医学中心谷歌学者
Foulkes MA, Davis CE:追踪纵向数据的指数。生物识别技术1981年,37:439 - 446。
谷歌学者
Tate RB, Manfreda J, Krahn AD, Cuddy TE:曼尼托巴大学1948-1988年的血压跟踪研究历时40年。美国流行病学杂志1995年,142:946 - 954。
中科院PubMed谷歌学者
Yong LC, Kuller LH, Rutan G, Bunker C:血压的纵向研究:青春期到中年的变化和决定因素。1957-1963至1989-1990年的多蒙特高中随访研究。美国流行病学杂志1993年,138:973 - 983。
中科院PubMed谷歌学者
曼顿KG,多德JE,斯塔拉德E:危险因素对中老年男女心血管风险的影响。在:预测老年人口的健康(编辑:Manton KG, Singer BH, Suzman RM)。纽约:Springer-Verlag 1993。
谷歌学者
知更鸟JM:复杂纵向数据的因果推断。见:潜在变量建模和因果关系的应用。统计学课堂讲稿(120)(编辑:Berkane M)。纽约:施普林格Verlag 1997。
谷歌学者
罗宾斯JM,格陵兰S:过量和病原学部分的可估计性和估计。医学统计学1989年,8:845 - 859。
中科院PubMed谷歌学者
Murray CJL, Acharya A:重新考虑健康差距中的年龄权重和折扣。见:人口健康的概要措施:概念、伦理、测量和应用(编辑:Murray CJL, Salomon J, Mathers CD, Lopez AD, Lozano R)。日内瓦:世界卫生组织,2002年。
谷歌学者
Kneese AV:浮士德交易。在:RFF阅读器在环境和资源管理(编辑:Oates WE)。华盛顿特区:未来资源(RFF) 1999。
谷歌学者
林德RC编著:能源政策中的时间和风险折现。巴尔的摩:约翰霍普金斯大学未来资源出版社1982.
Portney PR, Weyant JP编辑:折现与代际公平。华盛顿:面向未来的资源1999.
豪沃思RH:气候变化与世代重叠。当代经济政策1996年,14:100 - 111。
谷歌学者
谢林TC:代际打折。能源政策1995年,23:395 - 401。
谷歌学者
马托曼:长期贴现中的哲学与经济学调和。正确的观点:折现和代际公平(编辑:Portney PR, Weyant JP)。华盛顿特区:面向未来的资源1999。
谷歌学者
索洛RM:前言。正确的观点:折现和代际公平(编辑:Portney PR, Weyant JP)。华盛顿特区:面向未来的资源1999。
谷歌学者
帕菲特D:原因和人员。纽约:牛津大学出版社1984.
谷歌学者
莫瑞CJL,洛佩兹AD主编:全球疾病负担。马萨诸塞州剑桥:哈佛大学公共卫生学院(代表世界卫生组织和世界银行)1996.
Anand S, Hansen K:年龄权重和残疾调整生命年的折扣:一个重要的回顾。见:人口健康概要措施(编辑:日内瓦:世界卫生组织)。莫瑞文,马泽斯CD,洛佩斯AD,洛萨诺R 2002。
谷歌学者
库普曼斯TC:静止序数效用与不耐烦。费雪1960年,28:287 - 309。
谷歌学者
达斯古普塔P, Mäler K-G:贫困、制度与环境资源库。见:图书贫困、制度和环境资源库城市:世界银行1994年。
谷歌学者
达斯古普塔P, Mäler K-G,巴雷特S:代际公平、社会贴现率与全球变暖。正确的观点:折现和代际公平(编辑:Portney PR, Weyant JP)。华盛顿特区:面向未来的资源1999。
谷歌学者
Dasgupta P, Heal GM:可耗尽资源的最优消耗。经济研究综述1974年,41:
谷歌学者
索洛RM:代际公平与可耗尽资源。经济研究评论1974年,41:29-45。
谷歌学者
箭头KJ:折扣、道德和游戏。正确的观点:折现和代际公平(编辑:Portney PR, Weyant JP)。华盛顿特区:面向未来的资源1999。
谷歌学者
索洛RM:资源经济学或资源经济学。《美国经济评论》1974年,64:1 - 14。
谷歌学者
蒙哥马利WD:以市场为基础的贴现率:对布拉德福德的评价。正确的观点:折现和代际公平(编辑:Portney PR, Weyant JP)。华盛顿特区:面向未来的资源1999。
谷歌学者
Weitzman ML:继续打折,但是……正确的观点:折现和代际公平(编辑:Portney PR, Weyant JP)。华盛顿特区:面向未来的资源1999。
谷歌学者
Graham JD, Green LC, Roberts MJ:寻找安全:化学物质与癌症风险。剑桥:哈佛大学出版社1988.
谷歌学者
Kay D, Pruess AM, Corvalan CF:疾病环境负担评估方法。ISEE环境疾病负担会议。见:《疾病环境负担评估方法》一书。ISEE环境疾病负担会议城市:世界卫生组织(卫生组织),2000年。
谷歌学者
Ezzati M, Saleh H, Kammen DM:排放和空间微环境对肯尼亚生物质燃烧室内空气污染的贡献。环境卫生观点2000年,108:833 - 839。
中科院PubMed公共医学中心谷歌学者
皮托R:吸烟剂量和时间对肺癌发病率的影响里昂,法国:国际癌症研究机构1986.
谷歌学者
希尔阿瑟:环境与疾病:关联还是因果关系?英国皇家医学会会刊1965年,58:295 - 300。
中科院PubMed公共医学中心谷歌学者
国家研究委员会(NRC):风险评估中的科学与判断。华盛顿:国家学院出版社1994.
谷歌学者
罗宾斯JM,格陵兰S:评论A.P. Dawid的《没有反事实的因果推断》。美国统计协会杂志-理论与方法2000年,95:477 - 482。
谷歌学者
Law MR, Wald NJ, Thompson SG:血清胆固醇浓度降低多少和多快能降低缺血性心脏病的风险?英国医学杂志1994年,308:367 - 373。
中科院PubMed公共医学中心谷歌学者
霍顿R:常识和数字:医学有效性的修辞(1999年布拉德福德·希尔纪念演讲)。医学统计学2000年,19:3149 - 3164。
中科院PubMed谷歌学者
霍维茨RI,维斯科利CM,克莱门斯JD,萨多克RT:发展改进的治疗证据评价观察方法。美国医学杂志1990年,89:630 - 638。
中科院PubMed谷歌学者
霍维茨RI,辛格BH,维斯科利CM,马库奇RW:平均来说有益的治疗会对某些患者有害吗?临床问诊与药品监管信息需求冲突研究。临床流行病学杂志1996年,49:395 - 400。
中科院PubMed谷歌学者
Horwitz RI, Singer BH, Makuch RW, Viscoli CM:临床研究设计与分析中的临床与统计学考虑。临床流行病学杂志1998年,51:305 - 307。
中科院PubMed谷歌学者
布里顿A,麦基M,布莱克N,麦克弗森K,桑德森C,贝恩C:随机试验适用性的威胁:排斥和选择性参与。卫生服务研究与政策杂志1999年,4:112 - 121。
中科院PubMed谷歌学者
Britton A, McKee M:在东欧酒精和心血管疾病之间的关系:解释悖论。流行病学和社区卫生杂志2000年,54:328 - 332。
中科院PubMed公共医学中心谷歌学者
Thun MJ, Apicella LF, Henley SJ:吸烟与吸烟致死的其他危险因素:法庭上的混淆。美国医学会杂志2000年,284:706 - 712。
中科院谷歌学者
Morgan MG, Henrion M:不确定性:处理定量风险和政策分析中的不确定性指南。剑桥:剑桥大学出版社1990.
谷歌学者


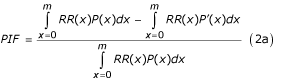

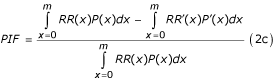


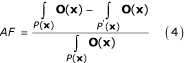

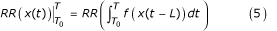
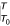 表示介于T0而且T”)。
表示介于T0而且T”)。





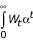 其中0 < α < 1在[
其中0 < α < 1在[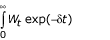 δ > 0在[
δ > 0在[