摘要
背景
云计算的不断发展为科学计算提供了新的机会,特别是对于分布式工作流。现代web浏览器现在可以用作高性能工作站,用于查询、处理和可视化基因组学的“大数据”,这些数据来自癌症基因组图谱(TCGA)和国际癌症基因组联盟(ICGC)等来源,而无需安装或配置本地软件。QMachine (QM)的设计是由于有机会在生物医学的关联数据网络的背景下使用这种普及计算模型。
结果
QM是一种开源的、公开可用的web服务,它充当通过HTTP发布任务和检索结果的消息传递系统。这里描述的说明性应用程序分发了20的分析链球菌引起的肺炎共享后缀的基因组。因为所有的分析和数据检索任务都是由志愿机器执行的,所以只需要很少的服务器资源。任何现代网络浏览器都可以提交这些任务和/或自愿执行它们,而无需安装任何额外的插件或程序。客户端库提供包括MapReduce在内的高级分发模板。这种完全脱离当前对运行“下载和安装”软件的昂贵服务器硬件的依赖已经引起了大量社区的兴趣,因为QM在12个月内收到了来自87个国家的220多万次API呼叫。
结论
QM被发现足以提供计算和数据密集型工作流程所需的可扩展生物信息学解决方案。矛盾的是,web浏览器的代码沙盒执行也被发现使它们作为计算节点,能够解决生物医学环境特征的关键隐私问题。
可用性
支持的QM部署可在https://v1.qmachine.org,其源代码可在https://github.com/wilkinson/qmachine.为现场演示提供了说明性示例及其依赖项http://q.cgr.googlecode.com/hg/index.html还有一个截屏和存档的基因组数据。
背景
生命科学领域的高性能计算(HPC)正在经历一场根本性的重塑。1]。对处理器密集型资源的依赖(不断扩大的基因组工作流程通过处理器密集型资源汇集)正在让位于分布式数据密集型基础设施,如TCGA和ICGC [2]。因此,涌入数据中心的不可移动的数据量需要“超越数据洪水”的解决方案[3.它颠覆了传统的传输模式,让计算传递到数据上,而不是反过来。因此,重点是最大限度地提高数据的可用性和应用程序的可移植性。生物医学应用中越来越多地使用云计算基础设施反映了高性能计算的重新调整,最近美国国立卫生研究院(NIH)与亚马逊在1000基因组计划上的合作就是一个例子[4]。
同时,HPC项目如SETI@home [5], Folding@Home [6]和BOINC [7已经构建了分布式平台,这些平台汇集了商品硬件和志愿计算周期,以便为计算密集型的科学工作流程提供动力。事实上,Folding@Home项目目前利用了来自25万多台个人电脑和视频游戏机的中央和/或图形处理单元[8]。为了在如此多的物理机器和硬件平台上协调集中的工作,研究人员提供了客户端应用程序,他们必须说服志愿者下载并永久安装在他们的机器上。这些应用程序的侵入性很广,从只在机器空闲时运行的程序,比如首创的SETI@home,到永远在线的后台服务,比如Condor []9这可能会对机器的性能产生切实的影响。
万维网为高性能计算提供了一条不同的途径,这就是我们在QM中所探索的——一个新颖的方向。为特定问题领域优化QM的诱惑被更大的挑战所克服,即创建一个系统不仅要跨Web分发计算,而且要“属于Web”本身。对作为平台的Web的仔细研究表明,必要的组件确实已经准备好进行组装。
JavaScript (JS)语言不仅是一种“真正的语言”[10也是“披着C语言外衣的口齿不清”[11支持函数式和面向对象的编程风格。然而,与Lisp不同的是,JS在学术界之外被广泛使用,并且在超过13年的时间里一直是最受欢迎的12种语言之一[12]。JS中的科学库相对较少,尽管有一些专业库,如EBI的BioJS [13], NIH/NHGRI JBrowse [14],以及最近的基因组图谱[15已经出现,利用这些计算资源的广泛可用性,特别是在基因组浏览应用领域。
Web浏览器在严格控制对机器资源访问的沙盒环境中执行JS,现在这些沙盒实现了提供硬件加速3D图形等本地功能的标准化api。所有现代浏览器,甚至一些浏览器插件都包括即时(JIT)编译器来提高性能[16]。例如,JS中的正则表达式在Perl不再匹配的级别上执行[17],在生物信息学应用中与字符串处理最相关的语言。此外,这些高性能JS环境已经预装在今天销售的每台个人电脑上,以及智能手机、平板电脑、游戏机,甚至电视上。因此,网络浏览器代表了高性能计算的现代路线,非常适合“众包”模式[18]。事实上,目前JS中生物信息学库的快速增长也反映了基于web的“社交编码”环境的出现,这为大规模协作提供了全新的机会[19]。此外,浏览器平台的网络功能允许它动态导入代码和数据,从而跨不同机器上的多个浏览器编排分布式工作流,这是社会计算的核心功能[20.]。因此,本报告所述的情况可解释为机器的社会计算[21],扩展松散分布模型(如mGrid)的范围[22]。
大数据在生物医学领域的出现与参考数据库的激增有关核酸研究[23]。综合数据模型,如分布式注释系统(Distributed Annotation System),已处理了独立于托管机构的关联数据网络资源的聚合。[24],我们也探索了它作为工作流组装的骨干[25]。然而,现在非常清楚的是,数据资源的链接,无论在哪个领域,本身都是领域中立的,并且最好由第三代Web技术基础的W3C资源描述框架(RDF)的二元谓词来描述[21,26,27]。
RDF方法扩展了对唯一资源标识符(uri)的基本依赖,以标识和定位数据(通过url),这只需要一个web浏览器,任何研究人员都可以很好地使用它,而不管他的专业知识或感兴趣的领域如何。欧洲生物信息学研究所(European Bioinformatics Institute)在所有数据服务中采用了RDF框架,这极大地说明了目前RDF的使用范围[28]。我们的一些工作也说明了这一点[29- - - - - -31在为TCGA开发SPARQL端点时,服务器端托管数据的数量并不是开发使用这些数据的web应用程序(“web应用程序”)的重大障碍。另一方面,尽管有像Taverna这样的优秀框架,但组装数据分析工作流的机制还没有成熟到用户友好的程度。[32]及分享[33]。一种可能性是,底层web服务本身需要能够随时进行组装——即使是对于已弃用或过时的过程版本也是如此。这是现代关注工作流程结果再现性的绝对要求[34]。我们已经探索了使用基于浏览器的模块化web应用程序在标准生物信息学应用程序(如图像分析)中提供此功能[35]和序列分析[36]。这两项努力的成功强化了这样一种说法,即脚本标签加载(web浏览器用来加载web应用程序的相同机制)可以跨多个物理机器协调和分发生物信息学工作流的执行。下面结果部分中详细介绍的说明性和验证性示例将通过分析20个不同的基因组来扩展这两个报告中的第二个中使用的序列分析示例链球菌引起的肺炎并行执行。
方法
QM将分布式计算平台作为web服务(PaaS)提供。它的体系结构(参见图1通过将表示/分析层与持久表示层解耦,将Web 3.0技术的一般模式与现代社交网站使用的模型结合起来,以便前者作为Web应用程序运行在客户端,该应用程序使用后者在服务器端提供的应用程序编程接口(API)。QM还解耦了web应用程序的表示层和分析层,以便第三方可以将QM web服务嵌入到他们自己的web应用程序中。

抽象的建筑。自组装QMachine的架构,突出显示处理(矩形)和传输带宽(箭头)的分布。QM不仅分配执行所需的计算周期n不同程序(Σ1、2、…n),还需要检索相应输入数据所需的带宽(D1、2、…n)从它们各自的url (d1、2、…n).该程序集由提交者启动,提交者发出一个密钥,该密钥得到许多自愿的web浏览器会话(V1、……n).然后,代码被传输到QM上的队列中,由自愿的浏览器拾取。
为了提供此功能,QM包含三个主要组件:API服务器、web服务器和网站。API和web服务器完全用JS编写,网站用HTML5, CSS和JS编写。QM的设计或接口没有将其绑定到特定的开发堆栈,但是我们希望将项目构建为真正的Web计算“设备”,这促使我们尽可能多地用JS实现代码。这一策略也带来了意想不到的回报;服务器端组件不需要对其运行的硬件和操作系统进行假设,这极大地简化了通过平台即服务(PaaS)部署到云的过程[37]。
本报告还提供了代码示例(参见Results),这些示例可以在嵌入QM web服务的任何网站上运行。这些例子都是用JS编写的,但其中一些也使用了CoffeeScript,“一种编译成JavaScript的小语言”[38]。许多常见的科学语言都可以翻译成JS,并且可以在JS中找到用于此目的的全面项目列表http://bit.ly/altjsorg.
API服务器
API服务器是一个响应客户端通过标准超文本传输协议(HTTP)发送的请求的程序。然后程序根据请求的方法、目标url和嵌入的数据来解释请求。QM的API提供了三种操作,如表所示1.作为POST的一部分发送的数据应该格式化为JavaScript对象表示法(JSON)格式;来自QM的响应数据也是json格式的。注意,客户机不一定是浏览器——任何可以通过HTTP通信和操作json格式数据的软件包都可以直接使用QM。
API服务器被实现为一个简单的Node.js [39程序,使用节点包管理器(NPM)从QM自己的公共可用模块“QM”加载并执行其所有应用程序逻辑。40]。该模块支持五种不同的数据库作为持久存储的目标:41]、MongoDB [42], PostgreSQL [43], Redis [44]和SQLite [45]。选择支持这五个开源数据库是基于它们的高性能和受欢迎程度,它们在设计上的差异有助于指导QM作为异构数据库环境的HPC解决方案的开发。MongoDB默认使用的替代实现的相对优点如下。CouchDB和MongoDB都是以文档为中心的NoSQL数据库,使用MapReduce api来理解JS,但是它们的设计非常不同。CouchDB不仅仅是一个数据库——它本身几乎足以实现QM,因为它捆绑了一个web服务器和一个http可访问的API。相比之下,MongoDB有一个模仿PostgreSQL和SQLite使用的传统关系风格的API,更侧重于集群和跨节点的“分片”(水平分区)。PostgreSQL代表关系数据库管理系统(RDBMS),它是传统上驱动企业应用程序和数据仓库的主力,而SQLite代表嵌入式(无服务器)数据库。Redis是一个内存中的键值存储,通常被称为“数据结构服务器”,因为它的键可以包含字符串、哈希、列表、集合和排序集合。在如此广泛的存储系统上映射QM的持久表示层的能力大大简化了部署和维护。支持本报告说明性示例的服务可在https://v1.qmachine.org,使用MongoDB。
QM的API服务器支持跨域资源共享[46]使任何网页都可以嵌入QM,在不违反同源策略的情况下跨浏览器分发工作流[47]。网页浏览器广泛支持CORS [48]。
Web服务器
web服务器和API服务器一样,是作为Node.js程序实现的,其逻辑包含在同一个NPM模块“qm”中。也就是说,只要运行Node内置的模块管理系统,就可以安装QMachine的所有基本库:NPM安装qm.值得回顾一下QM的服务器端组件所扮演的最小角色(参见图2)1结果)。web服务器的存在只是为了向客户端机器提供表示/分析层的资源。因为这些资源是静态的,所以web服务器可以被现成的web服务器(如Apache)所取代。49]和Nginx [50]。
网站
网站作为质量管理的展示/分析层。它是作为QM API的浏览器客户端开发的,因此它是用HTML5、CSS和JS实现的,这可以通过查看其源代码来验证https://github.com/wilkinson/qmachine.该网站由一个单独的网页组成,该网页使用一种称为异步JavaScript和XML (AJAX)的技术,通过XMLHttpRequest (XHR)周期性地与API服务器通信。但是,“AJAX”这个名称有点误导人,因为XHR并不局限于处理XML数据;所有浏览器客户端与API服务器的通信都使用JavaScript对象表示法(JSON)。
当浏览器加载网页时,它最初只加载由呈现图形用户界面(GUI)所需的HTML、CSS和JS资源组成的表示层。在GUI加载之后,浏览器立即检索QM的分析层,它完全是用JS编写的。这种设计通过更快地加载GUI改善了用户体验,并且将表示层的代码与分析层的代码隔离开来。因此,第三方可以嵌入QM的分析层,从而在不加载QM的表示层的情况下使用QM的持久表示层,如示例所示https://v1.qmachine.org/barebones.html和http://q.cgr.googlecode.com/hg/index.html.
QM的浏览器客户端将工作流建模为一组转换,这些转换应该以特定的顺序应用于输入数据以产生输出数据。“任务描述”是包含转换的对象f,数据x,以及在执行之前准备环境所需的任何信息。
如上所述,当指向浏览器时分发的客户端应用程序https://v1.qmachine.org仅使用web技术开发:HTML5, JS和CSS。为了保持所有浏览器和平台(包括移动设备)都支持的核心JS语法,代码开发由JSLint辅助[51]。JSLint还直接在分析层中用作静态分析工具,以识别可以忠实地序列化为JSON以分发给志愿机器的任务。一个通用的图书馆,Quanah [52],也是为了解决QM在异步数据传输中面临的众多并发性挑战而开发的;因此,它是这里描述的原型的关键组件,因此也可以通过开放源代码公开获得。表示层使用jQuery [53]和Twitter Bootstrap [54以确保在各种移动和桌面浏览器中保持一致的外观和感觉。该GUI还尝试通过与Google Chrome Frame的可选集成来支持过时的浏览器。55]、HTML5 Shiv [56]和json2.js [57,但这样做只是出于礼貌。
演示程序
演示程序是用纯JavaScript编写的,因此它可以在普通的web浏览器中运行,而不依赖于任何本地应用程序、插件或附加组件。它扩展了先前一项研究的论证[36],其中使用MapReduce分解序列分析程序来找到用户给定序列和完整细菌基因组之间最长的相似片段。本研究中的演示不仅将在另一台机器上使用远程执行再现先前的结果,而且还将对所有20个菌株并行执行链球菌引起的肺炎这些信息目前可以从国家生物技术信息中心(NCBI)获得。它使用与通用序列图(USM)相同的更新版本[58]库,直接引用其在线存储库中的准确版本。
结果
QMachine的体系结构如图所示1遵循Web 3.0技术的通用模式,将服务器端专门用于持久表示,而将其余的程序逻辑留在客户端运行。QM使用键-值体系结构以一种最大化分配数据传输和后续数据处理所需的计算资源的方式编排志愿客户机机器。此流程在图中突出显示1: QM不仅分配执行所需的计算周期n不同程序(Σ1、2、…n),还需要检索相应输入数据所需的带宽(D1、2、…n)从它们各自的url (d1、2、…n).这种设计的动机是生物应用的限制,如下一代测序,其中的限制因素往往是可用的内存而不是处理器的速度。
QM的操作依赖于创建唯一标识符来定义“框”,然后以类似于传统API密钥的方式与志愿浏览器共享这些“框”。该操作将在一系列四个增加复杂性的示例中进行描述,从(1)远程执行一个简单的代数操作开始,然后(2)将相同的操作作为数组元素的并行(map)转换进行分布,(3)再次作为MapReduce过程的一部分进行分布。最后,(4)并行执行现实世界的基因组序列分析,其中执行分析所需的代码和数据都由单个提交者调用,然后由多个志愿者浏览器完全解析和异步执行。最后一个实际示例分配处理和网络负载,如图所示2.它说明了自愿节点调用独立开发和维护的多个来源的代码和数据的能力。这个说明性的系列也可以在YouTube的网络直播中找到http://goo.gl/tnpMiQ.

现实世界基因组分析的工作流程。(1)提交者交互调用高层QM.map功能,从web浏览器与二十个不同的url链球菌引起的肺炎基因组作为输入,导致客户端向QM的API服务器提交20个单独的任务描述。(2)志愿者的浏览器在QM的API服务器上轮询新的任务描述,找到并下载任务描述。(3)志愿者的浏览器在下载三个外部资源后执行任务:GitHub提供的USM库,Google Code提供的JMat库,NCBI提供的细菌基因组。(4)志愿者的浏览器将任务执行的结果返回给QM的API服务器,并继续轮询新的任务描述。(5)提交者的浏览器轮询对单个任务描述的更新,从QM的API服务器检索结果。
加载客户端库
QM的分析层是由一个JS库提供的,它可以被任何web浏览器自动加载为包含以下代码的任何网页的一部分:
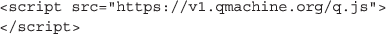
加载后,JS环境将包含一个名为QM使用方便的高级方法,可用于再现下面四个示例的结果。
(1)简单的代数运算
对于第一个说明性示例,让f是一个使给定数字递增的函数x除以2,然后x= 2。为了计算结果,f(x),在志愿者机器上,我们可以使用QM.submit方法:
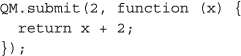
与本系列的其余部分一样,这个示例在附带的屏幕视频中进行描述和演示(http://goo.gl/tnpMiQ).还要注意,这个简单的操作很容易用其他语言表达,比如CoffeeScript [38):
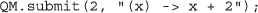
正如在“方法”中所讨论的,QM的架构并不强制使用特定的编程语言,只要使用编译器到JS,即web的“汇编语言”[35],是随远程调用分发的。为了支持这一说法,QM客户端库将CoffeeScript语言委托给一个用JS编写的编译器。有关可以将用其他语言编写的程序翻译成JS以便由自愿的浏览器解释的编译器列表,请参阅http://bit.ly/altjsorg.
(2)简单的分布式地图
因为每个QM.submit操作是异步调用,多个调用可以同时运行。因此,分配“map”函数的执行很简单,map是一种高阶函数模式,对数组的每个元素应用相同的操作。这种模式在科学计算中无处不在,因此需要一种专门的方法,QM.map,可以如下方式使用:
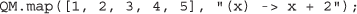
(3)简单的分布式MapReduce
正如上面所示的“map”函数一样,直接分配“reduce”函数的执行,这是一种高阶函数模式,一次组合两个数组元素,直到只剩下一个值。正如邹等人最近所做的调查。[59], MapReduce编程模板是现代计算密集型生物信息学应用的核心。第三个示例演示了MapReduce模式作为第二个示例的扩展,随后使用分布在QM志愿者之间的“reduce”对分布式“map”的结果进行求和:
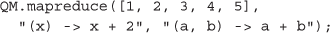
(4)真实世界基因组分析
第四个说明性示例评估了QM在实际生物信息学工作流中扩展上述异步操作的能力。示例是序列比对的分形MapReduce分解[36],它将处理和网络负载分配给QM的志愿者,如图所示1.它还演示了任何复杂性或精化的库都可以与调用这些库的命令一起分发给志愿者。具体来说,序列分析过程的数据和库编码都由QM调用,但完全由志愿浏览器解析和执行。它还说明了自愿节点调用来自独立开发和维护的多个源的代码和数据的能力。
像第一个例子一样,考虑我们有一些x我们希望通过某个函数进行变换f,所以x现在是一个引用由NCBI托管的FASTA文件的url数组:

我们想对每个FASTA文件执行一个特定的序列分析,即混沌博弈表示的分形MapReduce分解[36]。因此,我们定义了一个函数f用于QM.map方法,该方法将URL作为输入,并将序列分析的结果作为输出返回:
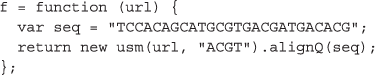
然而,在我们的功能中有一个关键的挑战f取决于超声电机只有在加载了外部库之后才存在的函数。因此,要完整地指定任务,我们需要包括超声电机作为f或者以URL的形式传递对库的引用。在这种情况下,我们选择了后一种策略,以便每个志愿者可以同时并行下载库,而不会给API服务器增加负担。每个外部函数可能有多个依赖项,因此QM.map接受可选的env参数,以便每个外部函数的依赖关系可以指定为顺序加载的url数组:
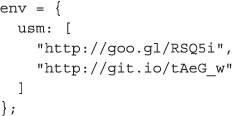
最后,我们将指定盒子参数,以便进行演示。的盒子参数代替API密钥,并允许志愿者在特定队列中执行任务。该机制允许提交者将任务定向到不同的队列中,并进一步支持使用像MapReduce这样的抽象:
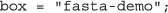
把这些定义放在一起,我们现在启动20个个体基因组序列分析,同时通过
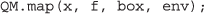
这些例子的完整版本可以在网上找到http://q.cgr.googlecode.com/hg/index.html.那里的版本包括所有20个的完整url链球菌引起的肺炎指定的版本库env.该页还提供了这些示例的附带视频。
使用情况统计
基于浏览器的工具在社交编码环境(如GitHub)中的传播[19[gm66nd]的特点是与社交媒体一样具有扩张性。例如,尽管这是我们描述它的第一份报告,但是整个社区可以——并且已经——发现QM。在2013年4月开始的12个月期间,QM收到了来自87个国家2100个IP地址的超过220万次API呼叫,超过1800个QM“盒子”(由令牌定义的代码和结果交换域),其中98个盒子接收超过1000次呼叫,16个盒子接收超过10,000次呼叫。QM使用情况统计如图所示3.,其用户的地理分布如图所示4.目前尚不清楚QM的使用究竟有多少与推动其发展的分布式计算基因组网络应用程序有关,但其用户的广泛地理分布表明,对分布式计算的更普遍兴趣推动了其吸引力。这种解释被HPC媒体中关于质量管理的主动报道所强化,例如HPCwire(文章http://goo.gl/9H5W03),insideHPC(http://goo.gl/bDkJZL).最后,正如方法中所指出的,所有服务器端和客户端软件都是开源的,并获得许可。浏览器客户端只需要在web应用中加载脚本标签,服务器端也可以通过NPM访问。40]。因此,可以想象,其他QM部署在其他地址,甚至可能在医疗中心的防火墙内使用,这是QM开发的具体意图。

使用数据的三种表示形式。该图显示了从2013年4月到2014年4月收集的日志数据中QMachine web服务的全球使用情况。对其应用程序编程接口(API)的调用超过220万次,其详细信息如表所示1.细实曲线表示按小时对其应用程序编程接口(API)服务器的调用次数;QM在大约79%的一小时时间段内处于空闲状态(没有接到任何呼叫),这些时间被忽略。细虚线表示按IP地址聚合的API调用的数量。粗虚线表示对QM上特定“框”进行的API调用的数量;有关QM框的详细信息,请参阅Results部分。

API调用的地理分布。这说明了按国家使用QMachine web服务作为世界地图。根据IP地址,共收到来自87个国家的访客的220多万次API呼叫。每个国家的绿色颜色根据其从高到低的排名从浅到深不等。
由于依赖于代码分发而不是代码执行,与编排这种最初大量使用QM相关的服务器负载非常小。实际上,支持上述使用统计信息的部署(后面的服务器)https://api.qmachine.org)从未被流量峰值压垮,即使它运行在共享租户虚拟机上,只有512 MB RAM, 2 × 512 MB MongoDB数据库,没有硬盘驱动器。此外,作者不会为公共工具传播(无论是从GitHub还是从NPM的包存储库)产生任何维护成本。因此,我们承诺不收集图中所述的广泛统计数据以外的任何数据3.和4用于此处讨论的参考部署。与推动这项工作的生物医学使用场景特别相关的是,我们还承诺不从私人部署的质量管理中收集任何数据;换句话说,QM软件的任何部分都不会从其他部署将数据发送回我们的服务器。这种设计允许管理员通过NPM部署自己的QM服务器,并根据临床和/或生物医学研究的需要完全配置自己的安全性。当然,这些保证可以通过检查质量管理的源代码来验证。
讨论
QMachine是一个用于执行分布式工作流的web服务,它可以使用普通的web浏览器作为众包超级计算机的临时计算节点。这里的想法很简单:配备了网络浏览器的普通计算机通过访问一个网站来加入一个抽象的机器,而它们通过导航到另一个网站或关闭浏览器来脱离。当浏览器仍然在站点上时,它通过执行JS对来自用户和站点后端基础设施的输入做出反应,这为抽象机器提供了一些执行计算的潜力。在任何时刻,高流量网站可用的净计算潜力都在HPC范围内,如图所示5.通过志愿者计算,QM使这种潜力得以利用,而且没有任何成本。

“500强”超级计算机的性能分布。这个直方图显示了“Top500”最快的超级计算机的浮点性能分布,以具有代表性的商用笔记本电脑为例。所使用的数据来自于2013年11月发布的榜单http://top500.org并与运行相同的LINPACK基准测试得到的结果进行比较[60]在普通笔记本电脑上(酷睿i7-2720QM, 8GB 1333MHz DDR3 SDRAM)。将真实世界的性能进行简单的划分,得出的估计性能是普通笔记本电脑的倍数。
MapReduce
许多可以访问大规模计算资源的研究人员仍然发现这些资源难以访问,因为“日常”工作流程通常需要的不仅仅是快速的计算机-它们需要更难获得的编程技能。生物信息学工作流程越来越依赖于MapReduce作为一种抽象,但是可用的MapReduce资源仍然将研究人员暴露在具有严格程序要求和陡峭学习曲线的编程环境中。QM比Apache Hadoop更容易设置和操作[61,例如。它允许用户在多台物理机器上运行MapReduce作业,并通过编写和加载网页的简单性将弹性计算资源众包——全世界数百万人每天都在执行这些技能。我们认为,使用QM探索的网络计算架构——也就是说,不安装专用的应用程序——是当前基于云的MapReduce服务的自然演变,就像Hadoop是从一次性编译和运行工作流的一个进步。
分布式计算
QM的web服务为分布式计算提供了一个消息传递接口。这句话乍听起来似乎有些矛盾,但JS的单线程编程模型并没有限制JS程序只能单线程执行;外部执行上下文可用于通过事件驱动编程支持并发性。QM利用浏览器的异步(非阻塞)网络通信层来连接多台机器的执行上下文,但是支持Web worker的浏览器[62可以在同一物理机内执行并发程序。
云浏览器
web计算架构发展中一个有趣的新转折是“云浏览器”的出现[63]。在这些系统中,当网页脚本需要大量计算时,移动浏览器表现为瘦客户端。因此,云浏览器在垂直方向上演示浏览器缩放,而QM则在水平方向上演示浏览器缩放。由于QM对其志愿者的底层资源没有任何假设,因此云浏览器可以与普通浏览器一起自愿为QM服务,而不会失去通用性。换句话说,云浏览器代表了当前浏览器的增强,而QM则为HPC提供了一种解决方案,将Web的底层架构推进到全球计算机的架构[64,65]。
生物医学应用
在临床环境中,分发工作流可能很困难,甚至不可能,因为隐私问题会阻止敏感数据离开医院环境,而传统的HPC通常不存在。QM在不需要额外资源的情况下满足了这种关注。如图所示5, 2013年11月Top500高性能计算机的计算能力中位数(http://goo.gl/XIUIDP)大约比我们实验室的标准台式计算机快2600倍。这是一个比典型医疗中心的机器数量小得多的因素。因此,即使限制在单个医院环境中,志愿者计算仍然可以与非常大量的HPC资源的总容量相媲美。
QM还可以用于为单个工作站内的工作流提供动力。在这样的场景中,工作站将在本地运行QM的API服务器,并使用多个浏览器选项卡并行执行工作流。这样的工作流程也可以纳入现有的生物信息学工具,如基本本地比对搜索工具(BLAST) [66]使用传统的服务器端脚本语言,如Perl [67]或Python [68连接到QM的API,甚至直接连接到持久存储层。
安全
使用QM的工作流的安全性通过志愿者的选择和对代码和数据的访问控制与QM垂直处理。然而,为了协助配置其分布式业务,应该考虑一些因素。重要的是要记住,web浏览器在沙盒环境中执行JS,在其他保护中,防止对志愿机器的文件系统进行编程访问。因此,QM的安全性是围绕两个防火墙配置的。
第一个也是最基本的保护与提交者发布的“盒子”(令牌)的唯一性有关,它应该只与受信任的志愿者共享。可以通过使用开放身份验证(如OAuth 2.0)来增加额外的安全层[69来验证只有受信任的志愿者参与其中。这第二层保护在创建审计跟踪时特别有用。这两种机制可以以多种方式组合在一起,以适合特定的工作流。例如,根据代码和数据的敏感性和/或志愿者的可信度,工作流的不同步骤可以分配给不同的志愿者群体。由此产生的粒度还可以用于在分布式QM操作中构建冗余,从而实现健壮性。
简而言之,质量管理体系结构中最薄弱的环节——也是被滥用的机会所在——来自于一组志愿者对“盒子”的共享。在这方面,QM设计的关键特征是滥用可以针对提交者而不是志愿者,因为QM的操作发生在web浏览器的沙箱中。
结论
QMachine的开发是为了应对生物医学环境中遇到的生物信息学应用的挑战和利用机遇。十多年来,志愿计算作为一种可扩展的、经济高效的高性能计算解决方案吸引了计算生物学的注意。QM本质上是将该解决方案移植到现代计算领域,该领域日益被移动硬件平台和使用web浏览器作为通用软件平台所主导。现代web浏览器的功能不仅仅是使其成为具有高级通信层的高性能计算环境;它们还包括一个变革性的特性,即计算在一个健壮的沙箱中运行,防止访问底层机器的潜在敏感文件系统。QM还响应了另一个现代趋势,即通过使用MapReduce编程模式,而不是通过与计算节点的直接交互,来使用HPC资源。本报告中说明QM使用的序列分析应用程序提供了一种直接的实用程序,可以使医学基因组学中的生物信息学应用受益。然而,有人认为,QM作为一种“网络的”分布式计算系统,在识别普适网络计算的基本特征方面可能同样有用。
支持数据的可用性
的链球菌引起的肺炎基因组数据直接从公开可用的在线存储库中使用http://ftp.ncbi.nlm.nih.gov/genomes/Bacteria/,有关FASTA文件也已存档至http://q.cgr.googlecode.com/hg/data/版本控制的存储库。原始数据用于生成图5都是从http://s.top500.org/static/lists/xml/TOP500_201311_all.xml并存档到http://q.cgr.googlecode.com/hg/data/.
源代码
本文的所有源代码都是版本控制和开源的。QMachine代码的主要来源位于Git [70]储存库https://github.com/wilkinson/qmachine.“结果”部分中显示的说明性示例的代码和数据可在Mercurial [71]储存库http://q.cgr.googlecode.com/hg/.Quanah的源代码存储库可在https://github.com/wilkinson/quanah, USM存储库可在https://github.com/usm/usm.github.com.
参考文献
Schadt EE, Linderman MD, Sorenson J, Lee L, Nolan GP:大规模数据管理和分析的计算解决方案。中国生物医学工程学报,2010,31(1):647-657。
莱德福德H:大科学:癌症基因组的挑战。自然科学,2010,34(4):972-974。[http://dx.doi.org/10.1038/464972a],
刘建军,刘建军,刘建军:数据泛滥后的世界。科学通报,2009,32(3):1297-1298。
Cravedi K, Randall T, Thompson L:亚马逊云上的1000个基因组项目数据。2012年,(http://www.genome.gov/27548042],
李建军,李建军,李建军,李建军。基于分布式计算的地外搜寻地外文明研究:SETI@home。生物天文学99,太平洋会议天文学会丛书第213卷。编辑:Lemarchand G, Meech K. 2000,旧金山:太平洋天文学会,511-511。
MR:潘德VS:全世界的屏幕保护程序,团结起来!科学,2000,31(4):1903-1904。
安德森DP: BOINC:一个公共资源计算和存储系统。第五届IEEE/ACM网格计算国际研讨会论文集,Grid ' 04。2004,华盛顿特区:IEEE计算机协会,4-10。[http://dx.doi.org/10.1109/GRID.2004.14],
Folding@Home项目统计。[http://fah-web.stanford.edu/cgi-bin/main.py?qtype=osstats],
Thain D, Tannenbaum T, Livny M:分布式计算的实践:秃鹰的经验。并发实践,2005,17(2-4):323-356。
Mikkonen T: Taivalsaari A:使用JavaScript作为一种真正的编程语言。技术代表,Sun Microsystems, Inc., Mountain View, CA, USA 2007;
Crockford D: JavaScript: The Good Parts. 2007, Sebastopol: O 'Reilly
TIOBE索引。[http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html],
Gómez J, Garcia LJ, Salazar GA, Villaveces JM, Gore SP, Castro AG, Martin MJ, Launay G, Alcántara R, del Toro N, Dumousseau M, Orchard SE, Velankar S, Hermjakob H, Zong C, Ping P, Corpas M, Jimenez RC:生物数据可视化的开源JavaScript框架。生物信息学,2013,29(8):1103-1104。[http://dblp.uni-trier.de/db/journals/bioinformatics/bioinformatics29.html#GomezGSVGGMLAdDOVHZPCJ13],
王晓明,王晓明,王晓明,等。基于JBrowse的新一代测序数据可视化。生物通报,2013,14(2):172-177。[http://bib.oxfordjournals.org/content/14/2/172.abstract],
马德娜,张建军,张建军,张建军,张建军,张建军,张建军,张建军,张建军,张建军,张建军。核酸学报,2013,41(1):441 - 446。[http://nar.oxfordjournals.org/content/41/W1/W41.abstract],
Rohlf C, Ivnitskiy Y:客户端即时引擎的安全挑战。网络安全学报,2012,30(2):884 - 886。[http://doi.ieeecomputersociety.org/10.1109/MSP.2012.53],
计算机语言基准游戏。[http://benchmarksgame.alioth.debian.org],
桑瑟姆C:众的力量。生物工程学报,2011,29(1):201-203。
Dabbish L, Stuart C, Tsay J, Herbsleb J: GitHub中的社交编码:开放软件存储库中的透明度和协作。ACM 2012计算机支持协同工作会议论文集,CSCW ' 12。2012,纽约:美国计算机学会,1277-1286。[http://doi.acm.org/10.1145/2145204.2145396],
Eysenbach G:医学2.0:社交网络、协作、参与、调解和开放。医学互联网学报,2008,(10):22-
[J]:从语义网到社会机器:万维网上人工智能的研究挑战。]情报学报,2010,34(4):559 - 561。
Karpievitch Y, Almeida J: mGrid:一个用于远程执行用户定义的Matlab代码的负载均衡分布式计算环境。生物信息学杂志,2006,7:139-[j]//www.mivven.com/1471-2105/7/139],
Galperin MY, Fernandez-Suarez XM:核酸研究数据库问题与在线分子生物学数据库收集。核酸学报,2012,40;
李建军,李建军,李建军,李建军。基于dna序列的生物信息学研究。生物信息学杂志,2007,8:333-
Veiga DFT, Deus HF, Akdemir C, Vasconcelos ATR, Almeida JS: DASMiner:从DAS数据源中发现和集成数据。中国生物医学工程学报,2009,32 (3):391 - 391
Hendler J: Web 3.0正在兴起。计算机学报,2009,42(2):111-113。
Hendler J, Holm J, Musialek C, Thomas G:美国政府链接开放数据:Semantic.Data.Gov。计算机工程学报,2012,27(4):559 - 561。
Jupp S, Malone J, Bolleman J, Brandizi M, Davies M, Garcia L, Gaulton A, Gehant S, Laibe C, Redaschi N, Wimalaratne SM, Martin M, Le novre N, Parkinson H, Birney E, Jenkinson AM: EBI RDF平台:生命科学的链接开放数据。生物信息学,2014,30(9):1338-1339。
Deus HF, Veiga DF, Freire PR, Weinstein JN, Mills GB, Almeida JS:基于SPARQL的肿瘤基因组图谱研究。生物医学通报,2010,43(6):998-1008。[http://www.sciencedirect.com/science/article/pii/S153204641000136X],
Robbins DE, gr
Saleem M, Padmanabhuni SS, Ngomo ACN, Almeida JS, Decker S, Deus HF:关联癌症基因组图谱数据库。第9届国际语义系统会议论文集,I-SEMANTICS ' 13。2013,纽约:美国计算机学会,129-134。[http://doi.acm.org/10.1145/2506182.2506200],
Hull D, Wolstencroft K, Stevens R, Goble C, Pocock M, Li P, Oinn T: Taverna:一个构建和运行服务工作流的工具。中国生物医学工程学报,2006,34(4):729-732。
王晓东,王晓东,王晓东,等。生物信息学的语义网络查询引擎。第四届亚洲语义网会议论文集,ASWC ' 09。2009,柏林,海德堡:Springer-Verlag, 367-369。[http://dx.doi.org/10.1007/978-3-642-10871-6_27],
彭RD:计算科学的可重复性研究。科学通报,2011,34(3):1226-1227。
陈建军,陈建军,陈建军,陈建军。基于生物信息学的图像生物信息学研究进展。中华病毒学杂志,2012,3:25-
张建军,张建军,张建军,等。基于分形MapReduce的序列比对分析。生物医学工程学报,2012,(7):12-
Lenk A, Klems M, Nimis J, Tai S, Sandholm T:云的内部是什么?云景观的建筑图。2009年ICSE云计算软件工程挑战研讨会论文集,Cloud ' 09。2009,华盛顿特区:IEEE计算机协会,23-31。[http://dx.doi.org/10.1109/CLOUD.2009.5071529],
CoffeeScript。[http://coffeescript.org/],
node . js。[http://nodejs.org/],
节点包管理器。[https://npmjs.org/],
Apache CouchDB。[https://couchdb.apache.org/],
MongoDB。[http://www.mongodb.org/],
PostgreSQL。[http://www.postgresql.org/],
复述。[http://redis.io/],
SQLite。[https://www.sqlite.org/],
跨域资源共享。[http://www.w3.org/TR/cors/],
JavaScript的同源策略。[https://developer.mozilla.org/en/Same_origin_policy_for_JavaScript],
我可以使用CORS吗?[http://caniuse.com/#feat=cors],
Apache HTTP服务器项目。[https://httpd.apache.org/],
Nginx。[http://nginx.com/],
JSLint。[http://www.jslint.com/],
jQuery。[http://jquery.com],
Twitter的引导。[http://twitter.github.com/bootstrap/],
谷歌Chrome框架。[https://www.google.com/chromeframe],
HTML5 Shiv。[https://code.google.com/p/html5shiv/],
json2.js。[https://github.com/douglascrockford/JSON-js],
通用序列图。[http://usm.github.com/],
邹强,李小兵,姜文荣,林志勇,李国良,陈凯:MapReduce框架操作在生物信息学中的研究进展。生物通报。2013,[http://bib.oxfordjournals.org/content/early/2013/02/07/bib.bbs088.abstract],
LINPACK基准测试。[http://www.top500.org/project/linpack/],
Apache Hadoop。[https://hadoop.apache.org/],
网络的工人。[http://www.w3.org/TR/workers/],
Tendulkar V, Snyder R, Pletcher J, Butler K, Shashidharan A, Enck W:滥用基于云的浏览器获取乐趣和利润。第28届计算机安全应用年会论文集,ACSAC ' 12。2012,纽约:ACM, 219-228。[http://doi.acm.org/10.1145/2420950.2420984],
安德森DP,库比亚托维兹J:全球计算机。科学通报,2002,36(3):40-47。[2002年3月号],
卡普·阿:全球计算机。第四届计算机创造、连接和协作国际会议论文集,C5 ' 2006。2006,华盛顿特区:IEEE计算机协会,112-119。[http://dx.doi.org/10.1109/C5.2006.41],
Perl程序设计语言。[http://www.perl.org/],
Python编程语言。[http://www.python.org/],
oth社区网站。[],
Git分布式版本控制系统。[http://git-scm.com/],
致谢
这项工作得到了阿拉巴马大学伯明翰分校临床与转化科学中心的部分支持。5UL1RR025777-03来自NIH国家研究资源中心。这项工作也得到了莱斯大学NCI T32培训生补助金的部分支持。5 t32ca096520-05。
作者信息
作者及单位
相应的作者
额外的信息
相互竞争的利益
作者宣称他们没有竞争利益。
作者的贡献
最初的概念源于JSA,两位作者都对QM的设计接口做出了重大贡献。SRW设计并实现了QM和Quanah, JSA设计并实现了USM。两位作者都编写了报告并测试了说明性示例。两位作者都阅读并批准了最终的手稿。
权利和权限
本文由BioMed Central Ltd.授权发表。这是一篇基于知识共享署名许可(http://creativecommons.org/licenses/by/2.0),允许在任何媒体上不受限制地使用、分发和复制,前提是原创作品要有适当的署名。创作共用公共领域免责声明(http://creativecommons.org/publicdomain/zero/1.0/)适用于本文中提供的数据,除非另有说明。
关于本文
引用本文
威尔金森,s.r.,阿尔梅达,J.S. QMachine:网页浏览器中的商品超级计算。BMC生物信息学15, 176(2014)。https://doi.org/10.1186/1471-2105-15-176
收到了:
接受:
发表:
DOI:https://doi.org/10.1186/1471-2105-15-176
关键字
- 云计算
- 众包
- 分布式计算
- JavaScript
- MapReduce
- PaaS
- 序列分析
- Web服务